KEDA - 基于 Kubernetes 的事件驱动自动缩放器
简介
KEDA(全称:Kubernetes-based Event Driven Autoscaler)是一个基于 Kubernetes 的事件驱动自动缩放器。 借助 KEDA,可以根据需要处理的事件数量来驱动 Kubernetes 中任何容器的扩展。
KEDA 是一个单一用途的轻量级组件,可以添加到任何 Kubernetes 集群中。 KEDA 与 Horizontal Pod Autoscaler 等标准 Kubernetes 组件一起工作,可以扩展功能而无需覆盖或重复。
借助 KEDA,您可以明确映射要使用事件驱动规模的应用程序,而其他应用程序继续运行。
优点:
- 为 Kubernetes 集群中的每个工作负载提供丰富的扩展能力
- 智能扩展您的事件驱动应用程序
- 适用于各种云平台、数据库、消息传递系统、遥测系统、CI/CD 等的 50 多个内置触发器
- 支持各种工作负载类型
- 支持跨各种云提供商和产品的触发器
原理图
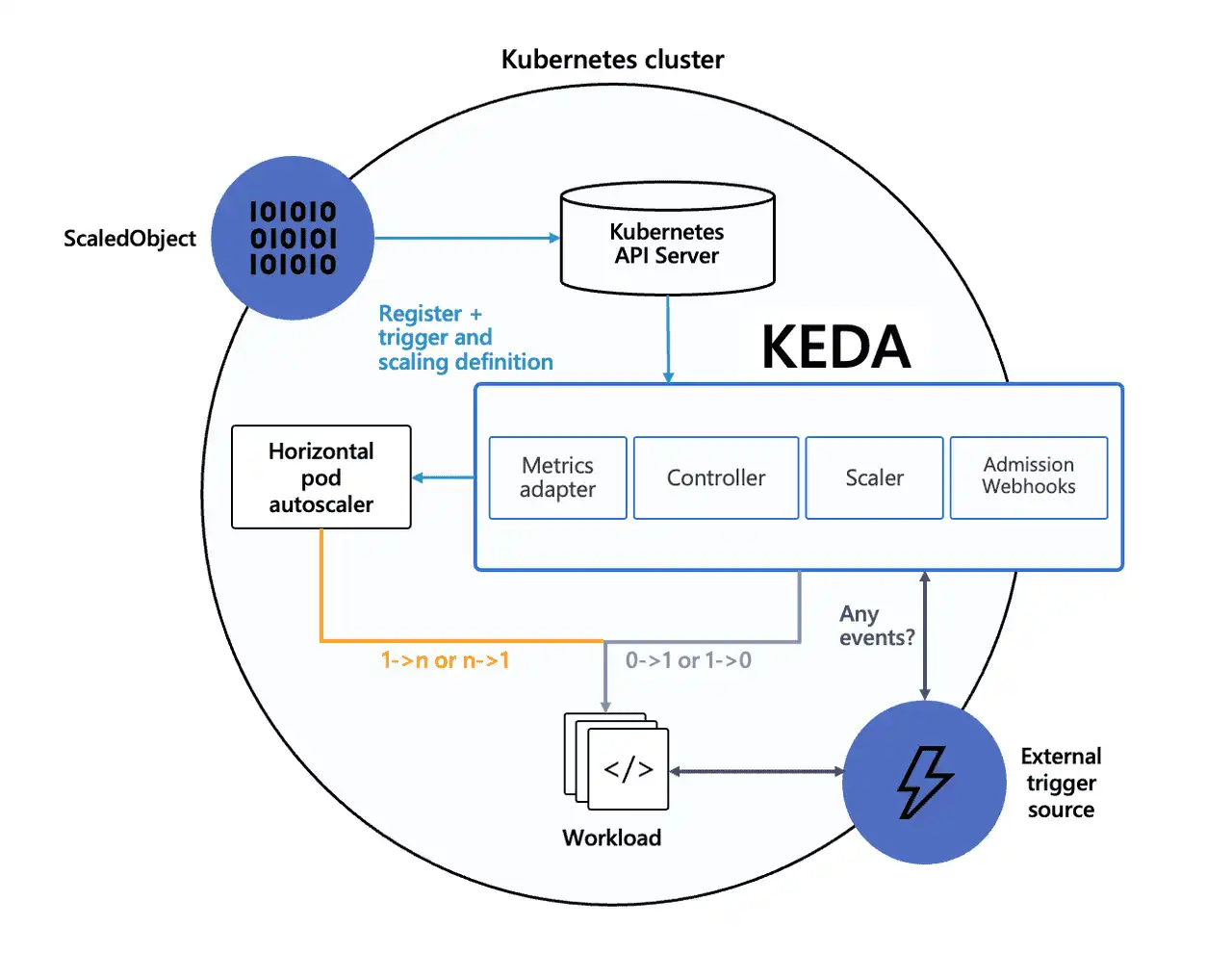
部署 Keda
使用 helm 部署
helm repo add kedacore https://kedacore.github.io/charts |
如果需要使用不同版本的 crd,可以访问 Keda Release 使用其中的 keda-2.xx.x-crds.yaml 文件
使用 Manifest 文件
访问 Keda Release 获取 Manifest 文件
其中 keda-2.xx.x.yaml 是包含所有功能的 Keda(包括Admission Webhooks)keda-2.xx.x-core.yaml 是安装所需的最少 KEDA 组件(不包含Admission Webhooks)
注意事项:
如果在 apply manifest 文件过程中出现了报错,请参考 ISSUE 使用 kubectl apply --server-side -f ...
CRD资源
安装 KEDA 时,它会创建四个自定义资源,这些自定义资源使您能够将事件源(以及对该事件源的身份验证)映射到 Deployment、StatefulSet、自定义资源或 Job 以进行扩展。
- scaledobjects.keda.sh:表示事件源(例如 Rabbit MQ)与 Kubernetes Deployment、StatefulSet 或定义 /scale 子资源的任何自定义资源之间所需的映射。
- scaledjobs.keda.sh:表示事件源和 Kubernetes Job 之间的映射。
- triggerauthentications.keda.sh:包含用于监视事件源的身份验证配置或 Secret。
- clustertriggerauthentications.keda.sh:包含用于监视事件源的身份验证配置或 Secret。
其中调度事件源如下所示:
apiVersion: keda.sh/v1alpha1 |
配置示例
如下的配置规定了一个名为 nginx 的 Deployment 的弹性伸缩,其中最小分片为 4,最大分片为 6,触发弹性伸缩的条件为 CPU 使用率达到 50% 以上持续 30 秒以上
关于 CPU 及内存的相关缩放,需要提供节点监控数据才可以使用,如部署 prometheus 的 metrics-server
apiVersion: keda.sh/v1alpha1 |
缩放器类别
参考官方文档:Scalers