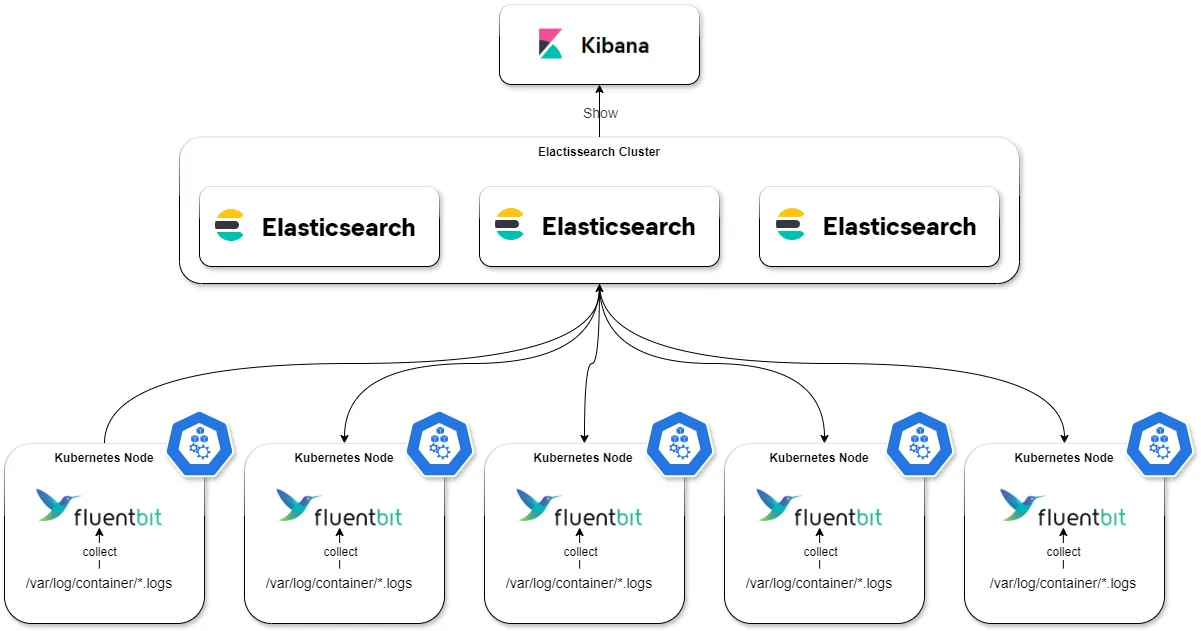
[FILTER] name lua match kube.* script scripts.lua call label_filter
[FILTER] name rewrite_tag match kube.* rule $log_tag ^(.*)$ $log_tag true
[FILTER] name lua match * script scripts.lua call remove_key_field
functionlabel_filter(tag, timestamp, record) if record["kubernetes"] == nilthen return0, timestamp, record end
local namespace = record["kubernetes"]["namespace_name"] local labels = record["kubernetes"]["labels"] local app = record["kubernetes"]["labels"]["app"] local log_tag = nil
if log_tag then record["log_tag"] = log_tag return2, timestamp, record else return0, timestamp, record end end
functionremove_key_field(tag, timestamp, record) fields_to_remove = {"stream", "kubernetes.pod_id", "kubernetes.docker_id", "kubernetes.container_hash", "kubernetes.container_image", "kubernetes.labels", "kubernetes.annotations"} for _, field inipairs(fields_to_remove) do local keys = {} for key instring.gmatch(field, "[^.]+") do table.insert(keys, key) end local current = record for i = 1, #keys - 1do current = current[keys[i]] ifnot current then break end end if current then current[keys[#keys]] = nil end end return1, timestamp, record end
[FILTER] name parser match java.* key_name log parser java_log reserve_data on
[FILTER] name parser match flink.* key_name log parser flink reserve_data on
[FILTER] name parser match nginx.* key_name log parser json reserve_data on
[PARSER] name java_log format regex regex /^(?<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3})(\s*)(?<loglevel>\w*)(\s*)\[(?<trace_id>\S*)\]\[[\w\-]*;(?<thread>[^\[\]\;]*);(?<span_id>\S*)\](\s*)(?<caller>\S*)(?<message>[\S\s]*)/ time_key time time_format %Y-%m-%d %H:%M:%S.%L time_keep On time_offset +0800
[PARSER] name flink format regex regex /^(?<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d{3})(\s+)(?<loglevel>\w+)(\s+)(?<classname>[\w\.]+)(?<message>[\S\s]*)/ time_key time time_format %Y-%m-%d %H:%M:%S,%L time_keep On
这里的正则 PARSER 需要根据自己的需要来配置
传输日志到 ES 或其他
[OUTPUT] name es match flink.jobmanager.* host 【ES HOST】 port 9200 index flink-jobmanager replace_dots on retry_limit 2 buffer_size 10mb tls on tls.verify off http_user elastic http_passwd 【密码】 suppress_type_name on trace_error on
[OUTPUT] name http match java.* host log-alert.logging.svc.cluster.local port 7000 uri /api/v1/receiver format json
parser-java-log.conf:| [FILTER] name parser match java.* key_name log parser java_log reserve_data on parser-flink-log.conf:| [FILTER] name parser match flink.* key_name log parser flink reserve_data on parser-nginx-log.conf:| [FILTER] name parser match nginx.* key_name log parser json reserve_data on es-output.conf:| [OUTPUT] name es match flink.jobmanager.* host 【ES HOST】 port 9200 index flink-jobmanager replace_dots on retry_limit 2 buffer_size 10mb tls on tls.verify off http_user elastic http_passwd 【密码】 suppress_type_name on trace_error on log-alert.conf:| [OUTPUT] name http match java.* host log-alert.logging.svc.cluster.local port 7000 uri /api/v1/receiver format json parsers.conf:| [MULTILINE_PARSER] name multiline_docker parser docker key_content log type regex flush_timeout 2000 rule "start_state" "/^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}(\.|\,)\d{3}(\s*)\w+/" "cont_state" rule "cont_state" "/^(?!\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}(\.|\,)\d{3}\s+\w+).*/" "cont_state" [PARSER] Namejson Formatjson Time_Keytime Time_Format%Y-%m-%dT%H:%M:%S.%LZ
scripts.lua:| function label_filter(tag, timestamp, record) if record["kubernetes"] == nil then return 0, timestamp, record end localnamespace=record["kubernetes"]["namespace_name"] locallabels=record["kubernetes"]["labels"] localapp=record["kubernetes"]["labels"]["app"] locallog_tag=nil iflabels~=nilthen iflabels["logging"]=="java"then log_tag=string.format("java.%s.%s",namespace,app) elseiflabels["component"]=="jobmanager"then log_tag=string.format("flink.jobmanager.%s.%s",namespace,app) elseiflabels["component"]=="taskmanager"then log_tag=string.format("flink.taskmanager.%s.%s",namespace,app) elseiflabels["logging"]=="nginx"then log_tag=string.format("nginx.%s",namespace) end end iflog_tagthen record["log_tag"]=log_tag return2,timestamp,record else return0,timestamp,record end end functionget_pod_ip(tag,timestamp,record) ifrecord["kubernetes"]["annotations"]andrecord["kubernetes"]["annotations"]["cni.projectcalico.org/podIP"]then record["podIP"]=record["kubernetes"]["annotations"]["cni.projectcalico.org/podIP"] return2,timestamp,record else return0,timestamp,record end end functionget_app_name(tag,timestamp,record) ifrecord["kubernetes"]["labels"]andrecord["kubernetes"]["labels"]["app"]then record["app"]=record["kubernetes"]["labels"]["app"] return2,timestamp,record else return0,timestamp,record end end functionremove_key_field(tag,timestamp,record) fields_to_remove= {"stream", "kubernetes.pod_id", "kubernetes.docker_id", "kubernetes.container_hash", "kubernetes.container_image", "kubernetes.labels", "kubernetes.annotations"} for_,fieldinipairs(fields_to_remove)do localkeys= {} forkeyinstring.gmatch(field,"[^.]+")do table.insert(keys,key) end localcurrent=record fori=1,#keys - 1 do current=current[keys[i]] ifnotcurrentthen break end end ifcurrentthen current[keys[#keys]]=nil end end return1,timestamp,record end