前言
Flink Kubernetes Operator 扩展了 Kubernetes API,能够管理和操作 Flink 部署,该 Operator 具有以下特点:
- 部署和监控 Flink Application 和 Session 的 Kubernetes Deployment
- 升级、暂停和删除 Kubernetes Deployment
- 完整的日志记录和指标集成
- 灵活的部署以及与 Kubernetes 工具的本机集成
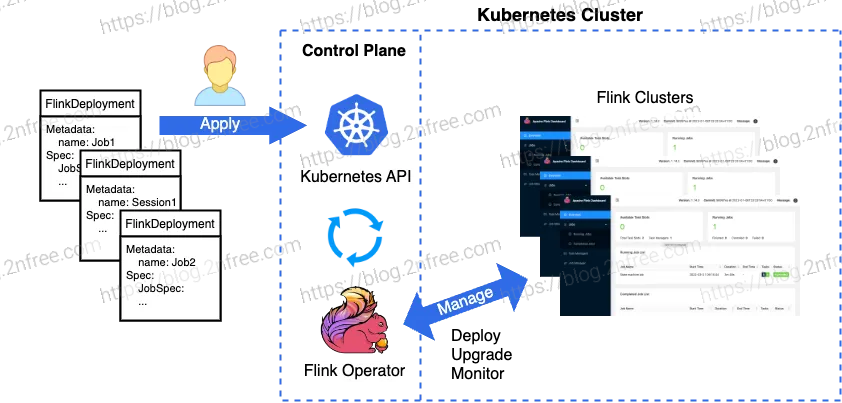
部署 flink operator
安装 cert-manager
在安装 flink operator 之前,需要在 Kubernetes 集群中安装 cert-manager,如果集群之前已经安装过 cert-manager,则无需安装
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.13.3/cert-manager.yaml
|
helm repo add jetstack https://charts.jetstack.io
helm repo update
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.13.3/cert-manager.crds.yaml
helm install cert-manager jetstack/cert-manager --namespace cert-manager --create-namespace --version v1.13.3
|
使用命令查看
kubectl get all -n cert-manager
NAME READY STATUS RESTARTS AGE
pod/cert-manager-57688f5dc6-gqjj6 1/1 Running 0 10m
pod/cert-manager-cainjector-d7f8b5464-h9gt9 1/1 Running 0 10m
pod/cert-manager-startupapicheck-hcth4 0/1 Completed 0 10m
pod/cert-manager-webhook-58fd67545d-knq2q 1/1 Running 0 10m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/cert-manager ClusterIP 10.110.70.247 <none> 9402/TCP 10m
service/cert-manager-webhook ClusterIP 10.104.112.12 <none> 443/TCP 10m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/cert-manager 1/1 1 1 10m
deployment.apps/cert-manager-cainjector 1/1 1 1 10m
deployment.apps/cert-manager-webhook 1/1 1 1 10m
NAME DESIRED CURRENT READY AGE
replicaset.apps/cert-manager-57688f5dc6 1 1 1 10m
replicaset.apps/cert-manager-cainjector-d7f8b5464 1 1 1 10m
replicaset.apps/cert-manager-webhook-58fd67545d 1 1 1 10m
NAME COMPLETIONS DURATION AGE
job.batch/cert-manager-startupapicheck 1/1 7m57s 10m
|
安装 flink-operator
flink operator 可以直接通过 helm 安装
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-<OPERATOR-VERSION>/
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.7.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator --namespace flink --create-namespace
kubectl get all -n flink
NAME READY STATUS RESTARTS AGE
pod/flink-kubernetes-operator-7bdcc785dd-rkvkw 2/2 Running 0 3m57s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/flink-operator-webhook-service ClusterIP 10.100.207.157 <none> 443/TCP 3m57s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flink-kubernetes-operator 1/1 1 1 3m57s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flink-kubernetes-operator-7bdcc785dd 1 1 1 3m57s
|
至此,flink operator 已经成功安装完毕
使用 flink operator 部署 flink job
在 flink operator 中,官方提供了 FlinkDeployment 和 FlinkSessionJobs 两种 CRD,可以部署基于 Application 模式或基于 Session 模式部署的 flink job
可以访问 https://github.com/apache/flink-kubernetes-operator/tree/main/examples 查看相关的示例
以下是两种不同模式部署的解析:
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: test-flink
spec:
image: flink:1.17
flinkVersion: v1_17
flinkConfiguration:
taskmanager.numberOfTaskSlots: "2"
taskmanager.memory.process.size: "6 gb"
taskmanager.memory.managed.fraction: "0.1"
state.savepoints.dir: file:///flinkdata/savepoints
state.checkpoints.dir: file:///flinkdata/checkpoints
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: file:///flinkdata/ha
execution.checkpointing.interval: 5 s
execution.checkpointing.timeout: 10 min
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.tolerable-failed-checkpoints: "2"
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: "3"
restart-strategy.fixed-delay.delay: 10 s
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
logConfiguration:
....
serviceAccount: flink
podTemplate:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
securityContext:
runAsUser: 9999
runAsGroup: 9999
fsGroup: 9999
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /flinkdata
name: test-flink-flinkdata
- mountPath: /opt/flink/downloads
name: downloads
volumes:
- name: test-flink-flinkdata
persistentVolumeClaim:
claimName: test-flink-flinkdata
- name: downloads
emptyDir: {}
jobManager:
resource:
memory: "2048m"
podTemplate:
apiVersion: v1
kind: Pod
metadata:
name: task-manager-pod-template
spec:
initContainers:
- name: wget
image: netdata/wget
volumeMounts:
- mountPath: /opt/flink/downloads
name: downloads
command:
- /bin/sh
- -c
- "wget -O /opt/flink/downloads/test.jar https://xxxx.com/test.jar"
taskManager:
resource:
memory: "6gb"
job:
jarURI: local:///opt/flink/downloads/test.jar
parallelism: 2
upgradeMode: last-state
state: running
|
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: test-flink
spec:
image: flink:1.17
flinkVersion: v1_17
jobManager:
resource:
memory: "2048m"
taskManager:
resource:
memory: "2048m"
serviceAccount: flink
---
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: test-job1
spec:
deploymentName: test-flink
job:
jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.16.1/flink-examples-streaming_2.12-1.16.1-TopSpeedWindowing.jar
parallelism: 4
upgradeMode: stateless
---
apiVersion: flink.apache.org/v1beta1
kind: FlinkSessionJob
metadata:
name: test-job2
spec:
deploymentName: test-flink
job:
jarURI: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.16.1/flink-examples-streaming_2.12-1.16.1.jar
parallelism: 2
upgradeMode: stateless
entryClass: org.apache.flink.streaming.examples.statemachine.StateMachineExample
|
Application 模式和 Session 模式的区别
Application 模式和 Session 模式的主要区别为是否需要实现高可用(High Availability,HA)
在使用 Application 模式时,每个 flink job 都会独占一个独立的 flink 集群,这个集群只运行这一个 flink 作业,并且可以通过持久化配置的方式,实现 HA
而 Session 模式为启动一个共享的 flink 集群,这个集群可以运行多个提交的 flink job,这样的好处是,无需每次都启动新的 flink 集群用于运行作业,但是并不能依靠 Operator 的方式来实现 HA,但是可以通过持久化相关数据来侧面实现
关于 Flink 的 HA 可以参考:https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/ha/overview/
访问 flink 集群
在 FlinkDeployment 启动后,会创建一个 xxx-rest 的 service 到 Kubernetes 集群内,其中 xxx 为 FlinkDeployment 的名称
可以通过配置 NodePort 或者 Ingress 的方式将该服务代理到集群外部以供访问
导出 flink 集群指标到 Prometheus
该步骤的前提条件为:集群中已经使用 prometheus-operator 安装了 prometheus 的相关组件
当我们在 FlinkDeployment 中配置如下配置时
...
spec:
image: flink:1.17
flinkVersion: v1_17
flinkConfiguration:
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
...
|
会在 flink 集群中开启指标导出的接口,默认端口为 9249,api 为 metrics,我们需要配置一个 Service 和 ServiceMonitor 来收集这些指标到 Prometheus
apiVersion: v1
kind: Service
metadata:
name: test-flink-metrics-service
namespace: flink
labels:
app: test-flink-metrics-service
spec:
ports:
- name: http-metrics
port: 9249
protocol: TCP
targetPort: 9249
selector:
app: test-flink
|
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: test-flink
namespace: monitoring
spec:
endpoints:
- port: http-metrics
interval: 10s
selector:
matchLabels:
app: test-flink-metrics-service
namespaceSelector:
matchNames:
- flink
|
dashboard 参考: